Reading a Very Large Csv File Into Pandas
Loading large datasets in Pandas
Effectively using Chunking and SQL for reading large datasets in pandas
![]()

The pandas' library is a vital fellow member of the Data Science ecosystem. Yet, the fact that it is un a ble to analyze datasets larger than memory makes it a little tricky for large data. Consider a situation when we desire to analyze a large dataset past using but pandas. What kind of problems can we run into? For instance, permit's take a file comprising 3GB of data summarising yellow taxi trip data for March in 2016. To perform whatever sort of analysis, nosotros will have to import it into memory. We readily employ the pandas' read_csv() office to perform the reading performance as follows:
import pandas equally pd
df = pd.read_csv('yellow_tripdata_2016-03.csv') When I ran the cell/file, my system threw the post-obit Retentivity Fault. (The retentivity error would depend upon the capacity of the arrangement that you lot are using).

Any Alternatives?
Earlier criticizing pandas, it is important to understand that pandas may non always be the right tool for every task. Pandas lack multiprocessing support, and other libraries are better at handling big information. One such alternative is Dask, which gives a pandas-like API foto work with larger than retention datasets. Even the pandas' documentation explicitly mentions that for big data:
information technology's worth considering not using pandas. Pandas isn't the right tool for all situations.
In this article, however, we shall look at a method called chunking, by which you can load out of retentiveness datasets in pandas. This method can sometimes offer a healthy way out to manage the out-of-retentivity trouble in pandas just may not piece of work all the time, which nosotros shall run across later in the chapter. Essentially nosotros will expect at ii ways to import big datasets in python:
- Using
pd.read_csv()with chunksize - Using SQL and pandas
💡Chunking: subdividing datasets into smaller parts
Before working with an example, let'due south endeavour and understand what we mean by the work chunking. According to Wikipedia,
Chunking refers to strategies for improving functioning by using special knowledge of a state of affairs to aggregate related memory-allocation requests.
In gild words, instead of reading all the data at once in the memory, we tin can divide into smaller parts or chunks. In the case of CSV files, this would mean only loading a few lines into the memory at a given point in time.
Pandas' read_csv() role comes with a clamper size parameter that controls the size of the clamper. Let's see it in action. We'll be working with the verbal dataset that we used earlier in the commodity, but instead of loading information technology all in a single get, we'll split up information technology into parts and load it.
✴️ Using pd.read_csv() with chunksize
To enable chunking, we will declare the size of the chunk in the beginning. Then using read_csv() with the chunksize parameter, returns an object nosotros can iterate over.
chunk_size=50000
batch_no=1 for chunk in pd.read_csv('yellow_tripdata_2016-02.csv',chunksize=chunk_size):
chunk.to_csv('clamper'+str(batch_no)+'.csv',index=False)
batch_no+=one
We choose a chunk size of fifty,000, which means at a time, only 50,000 rows of data will be imported. Hither is a video of how the main CSV file splits into multiple files.
Importing a unmarried clamper file into pandas dataframe:
We now accept multiple chunks, and each clamper tin can hands be loaded as a pandas dataframe.
df1 = pd.read_csv('chunk1.csv')
df1.head() Information technology works like a amuse!. No more memory error. Let's quickly look at the memory usage by this chunk:
df1.info() 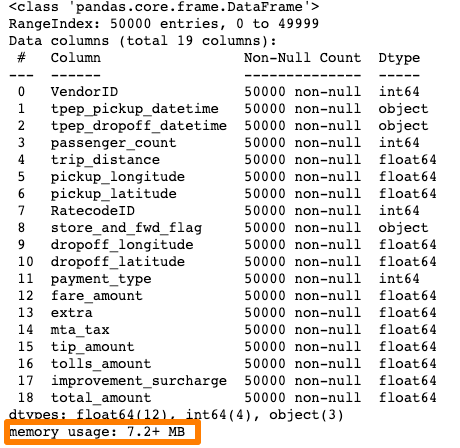
🔴 A word of circumspection
Chunking creates diverse subsets of the data. As a upshot, information technology works well when the operation you're performing requires nil or minimal coordination betwixt chunks. This is an important consideration. Another drawback of using chunking is that some operations like groupby are much harder to do chunks. In such cases, it is ameliorate to employ alternative libraries.
✴️Using SQL and pandas to read large data files¹
(encounter References)

Some other way around is to build an SQLite database from the chunks and then extract the desired data using SQL queries. SQLite is a relational database management system based on the SQL language simply optimized for small environments. It tin be integrated with Python using a Python module called sqlite3. If you want to know more about using Sqlite with python, you can refer to an article that I wrote on this very subject:
SQLAlchemy is the Python SQL toolkit and Object Relational Mapper that gives application developers the total power and flexibility of SQL. It is used to build an engine for creating a database from the original data, which is a big CSV file, in our case.
For this article, we shall follow the post-obit steps:
Import the necessary libraries
import sqlite3
from sqlalchemy import create_engine Create a connector to a database
Nosotros shall name the database to be created as csv_database.
csv_database = create_engine('sqlite:///csv_database.db') Creating a database from the CSV file with Chunking
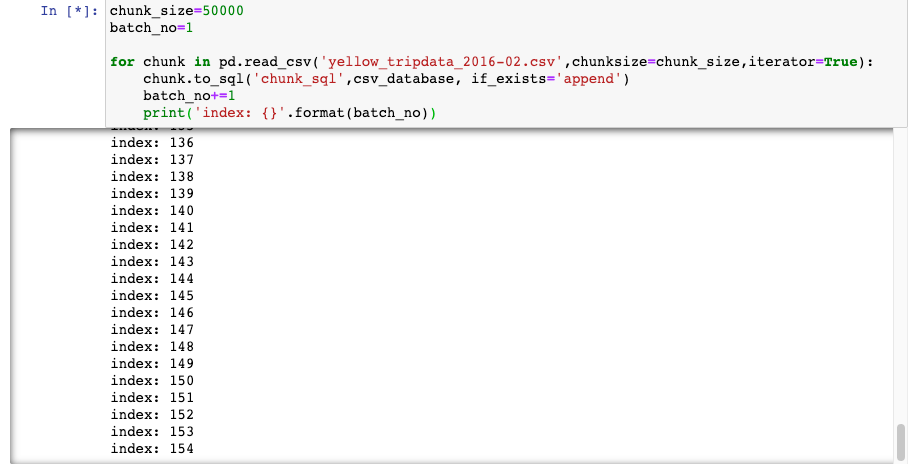
This process is similar to what we accept seen earlier in this article. The loop reads the datasets in bunches specified by the chunksize.
chunk_size=50000
batch_no=1 for chunk in pd.read_csv('yellow_tripdata_2016-02.csv',chunksize=chunk_size,iterator=Truthful):
clamper.to_sql('chunk_sql',csv_database, if_exists='suspend')
batch_no+=ane
print('index: {}'.format(batch_no))
Note that we use the function. chunk.to_sql instead of clamper.to_csv since we are writing the information to the database i.east csv_database.Also, chunk_sql is an arbitrary name given to the chunk.
Constructing a pandas dataframe by querying SQL database
The database has been created. We can now easily query it to extract only those columns that nosotros require; for instance, nosotros can excerpt only those rows where the passenger count is less than five and the trip distance is greater than ten. pandas.read_sql_queryreads SQL query into a DataFrame.
Nosotros now accept a dataframe that fits well into our memory and can exist used for further analysis.
Determination
Pandas is a handy and versatile library when it comes to information assay. All the same, it suffers from several bottlenecks when it comes to working with large data. In this article, we saw how chunking, coupled with SQL, could offer some solace for analyzing datasets larger than the system's memory. Still, this alternative is not a 'ane size fits all' solution, and getting to work with libraries created for handling big data would exist a amend choice.
Source: https://towardsdatascience.com/loading-large-datasets-in-pandas-11bdddd36f7b